 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnityMAS-O: A General RL Optimization Framework for LLM-Based Multi-Agent Systems
May 26, 2026LLM-based multi-agent systems decompose complex tasks into interacting roles, but most remain manually orchestrated by prompts, tools, and control rules, while agents are rarely optimized through a unified reinforcement learning interface. Existing RL post-training frameworks mainly target single-policy optimization and lack abstractions for user-defined multi-agent workflows, structured interaction, role-specific credit assignment, and configurable parameter sharing. We present UnityMAS-O, a general RL optimization framework for LLM-based multi-agent systems. UnityMAS-O treats the complete workflow as the optimization unit, rather than a single response or policy trajectory. It represents workflows through four first-class objects: logical agent roles, graph trajectories, user-defined rewards, and agent--model mappings. This decouples logical agents from physical model parameters, supporting full sharing, full separation, and partial sharing, with rewards assigned at role, turn, and trajectory levels. UnityMAS-O extends verl with a Ray-based star-topology runtime. A central controller executes workflows, invokes tools, records structured trajectories, and assembles rewards; model-local worker groups handle rollout, buffering, advantage computation, and distributed PPO-style updates. Users can define agents, workflows, model mappings, and rewards without rewriting the optimization infrastructure. We instantiate UnityMAS-O on retrieval-augmented QA, iterative agentic search, and reflective code generation. Across Natural Questions, HotpotQA, and held-out code tasks, multi-agent RL improves manually specified workflows after optimization, with especially large gains for smaller models and strict code all-passed metrics. These results show that UnityMAS-O can serve as a reusable substrate for converting diverse LLM-based multi-agent workflows into trainable multi-agent RL systems.
Tournament-GRPO: Group-Wise Tournament Rewards for Reinforcement Learning in Open-Ended Long-Form Generation
May 26, 2026Reinforcement learning in open-ended long-form generation is challenging because reliable reference answers and automatic metrics are often unavailable. Existing rubric-based methods typically rely on pointwise LLM-as-a-judge scoring, but absolute scores are difficult to calibrate across complex responses, may provide weak discrimination among same-query rollouts, and can become saturated during optimization. We propose Tournament-GRPO, a group-wise reward framework that converts rubric-guided LLM judgments into relative rewards through repeated multi-round tournaments among same-query rollouts. Tournament-GRPO compares candidates within groups, accumulates tournament outcomes, and normalizes them into group-wise rewards for GRPO training. Experiments on Deep Research Bench show that Tournament-GRPO consistently outperforms existing reward-design baselines, achieving a 4.52-point overall-score improvement over the strongest baseline. Further analyses show that tournament rewards provide a favorable effectiveness--efficiency trade-off and that tournament design affects training dynamics. These results suggest that rubric-guided tournament comparison provides an effective reward signal for reinforcement learning in open-ended long-form generation.
PRAISE: Prefix-Based Rollout Reuse in Agentic Search Training
Apr 04, 2026In agentic search, large language models (LLMs) are trained to perform multi-turn retrieval and reasoning for complex tasks such as multi-hop question answering (QA). However, current search-based Reinforcement Learning (RL) methods suffer from two core limitations: expensive long-horizon rollouts are under-utilized during training, and supervision is typically available only at the final answer, resulting in severe reward sparsity. We present Prefix-based Rollout reuse for Agentic search with Intermediate Step rEwards (PRAISE), a framework for improving both data efficiency and credit assignment in agentic search training. Given a complete search trajectory, PRAISE extracts prefix states at different search turns, elicits intermediate answers from them, and uses these prefixes both to construct additional training trajectories and to derive step-level rewards from performance differences across prefixes. Our method uses a single shared model for both search policy learning and prefix answer evaluation, enabling joint optimization without extra human annotations or a separate reward model. Experiments on multi-hop QA benchmarks show that PRAISE consistently improves performance over strong baselines.
JADE: Bridging the Strategic-Operational Gap in Dynamic Agentic RAG
Jan 29, 2026The evolution of Retrieval-Augmented Generation (RAG) has shifted from static retrieval pipelines to dynamic, agentic workflows where a central planner orchestrates multi-turn reasoning. However, existing paradigms face a critical dichotomy: they either optimize modules jointly within rigid, fixed-graph architectures, or empower dynamic planning while treating executors as frozen, black-box tools. We identify that this \textit{decoupled optimization} creates a ``strategic-operational mismatch,'' where sophisticated planning strategies fail to materialize due to unadapted local executors, often leading to negative performance gains despite increased system complexity. In this paper, we propose \textbf{JADE} (\textbf{J}oint \textbf{A}gentic \textbf{D}ynamic \textbf{E}xecution), a unified framework for the joint optimization of planning and execution within dynamic, multi-turn workflows. By modeling the system as a cooperative multi-agent team unified under a single shared backbone, JADE enables end-to-end learning driven by outcome-based rewards. This approach facilitates \textit{co-adaptation}: the planner learns to operate within the capability boundaries of the executors, while the executors evolve to align with high-level strategic intent. Empirical results demonstrate that JADE transforms disjoint modules into a synergistic system, yielding remarkable performance improvements via joint optimization and enabling a flexible balance between efficiency and effectiveness through dynamic workflow orchestration.
Beyond Monolithic Architectures: A Multi-Agent Search and Knowledge Optimization Framework for Agentic Search
Jan 08, 2026Agentic search has emerged as a promising paradigm for complex information seeking by enabling Large Language Models (LLMs) to interleave reasoning with tool use. However, prevailing systems rely on monolithic agents that suffer from structural bottlenecks, including unconstrained reasoning outputs that inflate trajectories, sparse outcome-level rewards that complicate credit assignment, and stochastic search noise that destabilizes learning. To address these challenges, we propose \textbf{M-ASK} (Multi-Agent Search and Knowledge), a framework that explicitly decouples agentic search into two complementary roles: Search Behavior Agents, which plan and execute search actions, and Knowledge Management Agents, which aggregate, filter, and maintain a compact internal context. This decomposition allows each agent to focus on a well-defined subtask and reduces interference between search and context construction. Furthermore, to enable stable coordination, M-ASK employs turn-level rewards to provide granular supervision for both search decisions and knowledge updates. Experiments on multi-hop QA benchmarks demonstrate that M-ASK outperforms strong baselines, achieving not only superior answer accuracy but also significantly more stable training dynamics.\footnote{The source code for M-ASK is available at https://github.com/chenyiqun/M-ASK.}
Leveraging LLMs to Evaluate Usefulness of Document
Jun 11, 2025The conventional Cranfield paradigm struggles to effectively capture user satisfaction due to its weak correlation between relevance and satisfaction, alongside the high costs of relevance annotation in building test collections. To tackle these issues, our research explores the potential of leveraging large language models (LLMs) to generate multilevel usefulness labels for evaluation. We introduce a new user-centric evaluation framework that integrates users' search context and behavioral data into LLMs. This framework uses a cascading judgment structure designed for multilevel usefulness assessments, drawing inspiration from ordinal regression techniques. Our study demonstrates that when well-guided with context and behavioral information, LLMs can accurately evaluate usefulness, allowing our approach to surpass third-party labeling methods. Furthermore, we conduct ablation studies to investigate the influence of key components within the framework. We also apply the labels produced by our method to predict user satisfaction, with real-world experiments indicating that these labels substantially improve the performance of satisfaction prediction models.
Exploring Human-Like Thinking in Search Simulations with Large Language Models
Apr 10, 2025Simulating user search behavior is a critical task in information retrieval, which can be employed for user behavior modeling, data augmentation, and system evaluation. Recent advancements in large language models (LLMs) have opened up new possibilities for generating human-like actions including querying, browsing, and clicking. In this work, we explore the integration of human-like thinking into search simulations by leveraging LLMs to simulate users' hidden cognitive processes. Specifically, given a search task and context, we prompt LLMs to first think like a human before executing the corresponding action. As existing search datasets do not include users' thought processes, we conducted a user study to collect a new dataset enriched with users' explicit thinking. We investigate the impact of incorporating such human-like thinking on simulation performance and apply supervised fine-tuning (SFT) to teach LLMs to emulate both human thinking and actions. Our experiments span two dimensions in leveraging LLMs for user simulation: (1) with or without explicit thinking, and (2) with or without fine-tuning on the thinking-augmented dataset. The results demonstrate the feasibility and potential of incorporating human-like thinking in user simulations, though performance improvements on some metrics remain modest. We believe this exploration provides new avenues and inspirations for advancing user behavior modeling in search simulations.
RecGPT: Generative Personalized Prompts for Sequential Recommendation via ChatGPT Training Paradigm
Apr 06, 2024ChatGPT has achieved remarkable success in natural language understanding. Considering that recommendation is indeed a conversation between users and the system with items as words, which has similar underlying pattern with ChatGPT, we design a new chat framework in item index level for the recommendation task. Our novelty mainly contains three parts: model, training and inference. For the model part, we adopt Generative Pre-training Transformer (GPT) as the sequential recommendation model and design a user modular to capture personalized information. For the training part, we adopt the two-stage paradigm of ChatGPT, including pre-training and fine-tuning. In the pre-training stage, we train GPT model by auto-regression. In the fine-tuning stage, we train the model with prompts, which include both the newly-generated results from the model and the user's feedback. For the inference part, we predict several user interests as user representations in an autoregressive manner. For each interest vector, we recall several items with the highest similarity and merge the items recalled by all interest vectors into the final result. We conduct experiments with both offline public datasets and online A/B test to demonstrate the effectiveness of our proposed method.
USimAgent: Large Language Models for Simulating Search Users
Mar 14, 2024



Due to the advantages in the cost-efficiency and reproducibility, user simulation has become a promising solution to the user-centric evaluation of information retrieval systems. Nonetheless, accurately simulating user search behaviors has long been a challenge, because users' actions in search are highly complex and driven by intricate cognitive processes such as learning, reasoning, and planning. Recently, Large Language Models (LLMs) have demonstrated remarked potential in simulating human-level intelligence and have been used in building autonomous agents for various tasks. However, the potential of using LLMs in simulating search behaviors has not yet been fully explored. In this paper, we introduce a LLM-based user search behavior simulator, USimAgent. The proposed simulator can simulate users' querying, clicking, and stopping behaviors during search, and thus, is capable of generating complete search sessions for specific search tasks. Empirical investigation on a real user behavior dataset shows that the proposed simulator outperforms existing methods in query generation and is comparable to traditional methods in predicting user clicks and stopping behaviors. These results not only validate the effectiveness of using LLMs for user simulation but also shed light on the development of a more robust and generic user simulators.
Brand Celebrity Matching Model Based on Natural Language Processing
Aug 18, 2022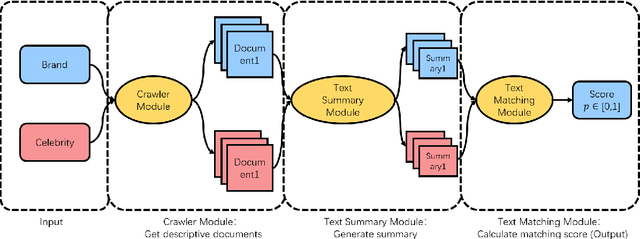


Celebrity Endorsement is one of the most significant strategies in brand communication. Nowadays, more and more companies try to build a vivid characteristic for themselves. Therefore, their brand identity communications should accord with some characteristics as humans and regulations. However, the previous works mostly stop by assumptions, instead of proposing a specific way to perform matching between brands and celebrities. In this paper, we propose a brand celebrity matching model (BCM) based on Natural Language Processing (NLP) techniques. Given a brand and a celebrity, we firstly obtain some descriptive documents of them from the Internet, then summarize these documents, and finally calculate a matching degree between the brand and the celebrity to determine whether they are matched. According to the experimental result, our proposed model outperforms the best baselines with a 0.362 F1 score and 6.3% of accuracy, which indicates the effectiveness and application value of our model in the real-world scene. What's more, to our best knowledge, the proposed BCM model is the first work on using NLP to solve endorsement issues, so it can provide some novel research ideas and methodologies for the following works.